0. Introduction
아래 book study는 알 스웨이가트가 지었고, 박재호님이 번역하신 클린 코드, 이제는 파이썬이다. 를 읽고 진행한 book study 입니다. 영문 원본으로 온라인 공개된 자료가 있어서 영문으로 학습합니다.
기존에 읽었던 Clean Code는 자바 코드로 되어 있어서, 먼저 파이썬 클린 코드를 학습 후 시작할려고 합니다.
이번 book study를 진행하면서 code에 대한 철학이 생기고, code를 바라보는 눈이 깊어지고, 넓어지기를 바랍니다.
각 chapter를 읽고 내용 정리하는 식으로 진행합니다.
이번에 학습하는 chapter의 주제는 ‘Chapter 07: Programming Jargon - 파이썬 세상의 프로그래밍 언어’ 입니다.
파이썬 용어집: https://docs.python.org/3/glossary.html 참고하기
파이썬 객체 설명: https://docs.python.org/3/reference/datemodel.html 참고하기
본격적으로 시작하기 전에 ‘전문 용어’에 대해서 생각을 잠시 해보자. 이 ‘전문 용어’를 풀어서 설명할 수 있다. 하지만, 그러기 시작하면 문장이 길어져서 일하기가 어려워진다. 그래서 약어를 선호하게 되고, 전문 용어를 선호하게 된다.
그래서 이번 장에서는 파이썬에서 사용되는 프로그래밍 언어의 전문 용어의 의미를 짚어본다. 그 이유는 소프트웨어 개발의 용어와 파이썬 세상의 프로그래밍 용어가 미묘하게 의미 차이가 있기 때문이다. 그래서 이번 장에서는 파이썬과 관련된 용어만 다룬다.
1. 각종 용어 정의
각종 용어에 대한 공식 문서 정의는 이 링크를 참고한다.
프로그래밍 언어로서 파이썬 vs 인터프리터로서 파이썬
‘파이썬이 프로그램을 실행한다’ 또는 ‘파이썬이 예외를 발생시킨다’ 에서 파이썬은 .py 파일의 코드를 읽고 수행하는 실제 소프트웨어인 파이썬 인터프리터를 의미한다.
그리고, 파이썬 인터프리터는 파이썬 소프트웨어 재단이 관리하며 www.python.org 에서 다운받을 수 있는 C파이썬(CPython)을 의미한다. 이 인터프리터를 구현체(implementation) 라고 한다.
구현체의 종류에는 C 프로그래밍 언어로 된 C파이썬, java로 작성된 Jython, 프로그램 실행됨에 따라 컴파일하며 파이썬으로 작성된 PyPy가 있다.
가비지 컬렉션
프로그래밍 언어는 수동적으로 메모리 할당과 할당 해제 과정을 사람이 직접 지시를 내려야 했다. 그래서 사람이 이를 잊으면 메모리 누수 같은 많은 버그를 일으켰다.
하지만, 이제는 가비지 컬렉션(garbage collection) 이 존재하기 때문에, 메모리 할당과 해제를 해야하는 시점을 추적하여 프로그래머의 부담을 덜어주는 자동화된 메모리 관리 기법 을 말한다.
| |
위 함수를 호출하는 순간 spam 이라는 변수가 메모리에 올라가고, 호출이 반환되면 로컬 변수를 해제해서 다른 데이터가 해당 메모리를 사용 가능하도록 한다.
리터럴
리터럴 이란? 사람이 직접 손으로 작성한 ‘고정 값’을 나타내는 소스 코드 텍스트에 나타나는 값 이라고 생각하면 된다. 파이썬 소스 코드에는 내장 데이터 형식만 리터럴 값을 가질 수 있으므로, 변수 age는 리터럴 값이 아니다. 42와 ‘Zophie’는 literal이다.
| |
키워드
모든 프로그래밍 언어에는 언어만의 고유의 키워드를 가진다. 이를 예약어라고 부른다. 이 키워드들은 변수명으로 사용해서는 안된다.
🔆 객체, 값, 인스턴스, 아이디
객체 는 데이터를 표현하는 것인데, 여기서 데이터란 복잡한 데이터 구조 전부를 포함하여 의미한다.
모든 객체에는 값(value), 아이디(identity), 데이터 타입(data type) 이 존재한다.
아래의 spam 은 변수지만, ['cat', 'dog', 'moose'] 라는 값을 가진 리스트 객체가 포함된 변수라고 말할 수 있다.
| |
새로운 값을 spam에 지정하니 id 값이 바뀌었다.
spam이라는 식별자들은 동일한 객체를 참조할 수 있기 때문에, 아이디와는 전혀 다르다.
그러면 동일한 객체를 참조하는 두 식별자의 id값은 어떨까?
| |
동일한 딕셔너리 객체를 참조하기 때문에 id는 동일하다.
이런 상황에서 spam이 참조한 객체의 값을 변경하면?
| |
spam만 변경되었는데, eggs도 변경되었다. 그 이유는 두 식별자가 동일한 객체를 참고하기 때문이다.
변수는 값의 보관소(container)가 아니라 엄밀히 말하면 값의 참조다. 변수를 설명할 때, 상자로 흔히들 설명하는데 이보다는 아래 이미지처럼 레이블로 생각해보자. 여러 변수가 하나의 객체를 가리킬 수 있으므로 그 객체는 여러 변수에 저장될 수 있다.
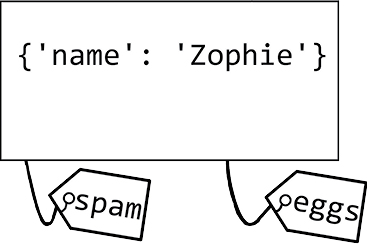
그래서 항상 할당 연산자(assignment operator)는 객체가 아닌 참조를 복사한다는 사실을 이해하지 못한채, 객체의 복사본을 만든다고 생각하여 버그를 유발할 수 있다.
| |
동일한 값을 spam과 bacon이 가졌다고 해도, 엄연히 다른 객체다. 그래서 맨 마지막에 False가 뜬 것이다.
bacon과 spam이 동일한 id를 가지기 원한다면 다음과 같이 작성한다.
| |
아이템
list나 dictionary 처럼 컨테이너 객체 안에 있는 객체를 파이썬에서는 아이템(item) 또는 원소(element)라고 부른다. ['dog', 'cat', 'moose'] 내의 문자열은 객체지만 아이템, 원소라고도 부른다.
가변 데이터 타입, 불변 데이터 타입
파이썬의 모든 객체는 값, 데이터 타입, 아이디를 가지며 이 중에서 값만 변경할 수 있다. 값을 변경할 수 있으면 mutable 객체이며, 변경할 수 없으면 immutable 객체다.
| 가변 데이터 타입 | 불변 데이터 타입 |
|---|---|
| 리스트(list) | 정수(Integer) |
| 딕셔너리(Dictionary) | 부동소수점(Floating-point number) |
| 집합(set) | 부울(Boolean) |
| 바이트 배열 | 문자열(string) |
| 배열(Array) | 고정집합(Frozen set) |
| 튜플(tuple) | |
| 바이트(Byte) |
String
아래 두 문자열 객체는 서로 다르므로 각기 다른 id를 가진다.
| |
기존 문자열에 새로운 문자열을 더하는 연산도 다른 id 값을 가지게 된다.
List
하지만, 가변 객체를 가리키는 변수 안의 값은 in-place 방식으로 수정될 수 있다.
| |
이 리스트도 id 값이 바뀌는 경우가 있다. 바로 + 연산자를 사용해 리스트를 연결하는 경우다. 하지만 이 또한 .extend() method를 사용하면 id값이 변경되는 것 없이 값만 수정된다.
| |
extend method로 list를 추가하면 id값이 바뀔 것 같지만, 그렇지 않았다.
+ 연산을 하면서 id 값이 변경되지 않기 위해서는 += 연산자를 사용하면 된다.
Tuple
| |
하지만 tuple의 내부 list는 가변이기 때문에 수정할 수 있다.
| |
인덱스, 키, 해시
list
list의 원소에 접근하기 위해서는 인덱싱을 해야하는데 이 때 **대괄호([])**를 사용한다.
인덱스는 0 기반 인덱스 를 사용한다.
dictionary, tuple
dictionary에서 인덱싱은 key 값을 사용한다. 그래서 해시 가능한 객체가 될 수 있다.
객체의 해시는 객체의 수명 주기 동안 절대로 변하지 않으며, 객체의 값이 같다면 해시도 반드시 같아야 한다. 이 값을 기준으로 해시를 반환하기 때문이다. 그래서 객체의 id는 달라도, 값이 같으면 해시는 같다.
해시가 가능한 대상은 immutable data type(ex: string, integer, tuple …)만 가능하다. 그래서 딕셔너리에서는 해시 가능한 아이템만 키로 사용할 수 있고, 해시 불가능한 리스트가 포함된 튜플은 키로 사용할 수 없다.
| |
컨테이너, 시퀀스, 매핑
파이썬에서 컨테이너, 시퀀스, 매핑, 집합 타임은 무엇일까?
컨테이너: 여러 종류의 객체를 포함할 수 있는, 즉 어떤 데이터 타입이든 포함할 수 있는 객체 ex)list, dictionary, tuple..
시퀀스: 순서가 있어서 정수 인덱스를 통해 원소에 접근이 가능한 컨테이너 데이터 타입의 객체 ex) list, tuple..
매핑: 인덱스 대신 키를 사용하는 컨테이너 데이터 타입의 객체 ex) dictionary
- 매핑은 3.6버전부터는 정렬되었지만, 그 이전에는 정렬되지 않았다.
- 매핑이 정렬되었다는 건 딕셔너리의 키-값 쌍의 삽입 순서가 유지된다는 것이다.
- 하지만 그렇다고 인덱스를 통해 원소에 접근할 수 있는 건 아니다.
- 파이썬에서 매핑 유형은 매우 다양하다: OrderedDict, ChainMap, Counter, UserDict 등등
이중밑줄 메소드, 매직 메소드
위 메소드들은 파이썬에서 이름의 앞 뒤에 2개의 밑줄(_)이 붙는 특수한 메소드를 말한다.
주로 연산자 오버로드에 사용된다.
Dunder는 Double UNDERscore의 줄임말이다.
가장 익숙한 dunder method인 __init__은 객체를 초기화한다.
17장에서 자세히 설명한다.
모듈, 패키지
모듈은 다른 파이썬 프로그램이 해당 모듈의 코드를 사용할 수 있게 해주는 기능을 말한다.
파이썬과 함께 설치되는 모듈들을 총칭하여 파이썬 표준 라이브러리라고 한다.
패키지는 __init__.py라는 이름의 파일 담겨진 폴더 안에 있는 모듈들의 집합을 말한다.
호출가능 객체, 일급 객체
호출 가능 객체
호출가능 연산자(callable operator)를 구현하는 모든 객체는 호출가능 객체다.
호출가능 연산자란 ()를 말한다.
일급 객체
파이썬에서 함수는 일급 객체(first-class object)이므로, 변수에 저장되고 함수 호출에서 인수로 전달되고, 함수 호출 결과로 반환되는 등 객체로 할 수 있는 모든 기능을 할 수 있다.
| |
이 방식은 주로 함수 이름을 변경할 때 사용된다. 상당 수의 기존 코드가 예전 이름을 쓰고 있으며, 옛 이름을 변경하기 힘들 경우 별칭을 활용한다.
그 외에 일급 함수를 사용하는 이유 는 함수를 다른 함수에 인자로 넘기기 위함 이다.
아래 코드를 보자.
| |
2. 흔히 혼동되어 사용되는 용어
문(statement) vs 표현식(expression)
expression은 값들과 연산자들로 구성된 명령어로, 변수이거나 값을 가지거나 함수 호출로 값을 반환하는 것들을 말한다.
| |
하지만 statement는 값으로 도출되지 않는 모든 명령으로, 다른 함수에 인수로 전달될 수 있고, 변수에 할당할 수 있다.
if 문, for 문, return 문 등의 표현식이 포함된다.
블록 vs 절 vs 바디
블록(block) 은 들여쓰기로 시작하여 해당 들여쓰기 수준이 이전 들여쓰기 수준으로 돌아오면 종료된다.
for 문, if 문에 따라나오는 코드를 해당 문(statement)의 블록 이라고 한다.
공식 문서에서는 모듈, 함수, 클래스 같이 한 단위로 실행하는 파이썬 코드 조각을 지칭하는데는 블록을 사용한다.
한 편으로는 파이썬 공식 문서에서는 블록보다는 ‘절(clause)’ 이라는 용어를 선호한다.
아래 코드를 보면 if 문은 clause header(절 헤더) 이고, 그 아래 오는 부분은 clause suite 또는 바디(body) 라고 한다.
| |
변수 vs 속성
변수: 객체를 가리키는 이름
속성: 점(.) 다음에 나오는 모든 이름이기 때문에 객체(점/마침표 앞에 위치하는 이름)와 연관된다.
| |
위 코드에서 spam은 datetime을 포함하는 변수다.
year, month는 해당 객체의 속성이다.
함수 vs 메서드
method는 클래스와 연관된 일종의 function이다.
| |
위 예제에서 len()은 함수이고, upper()는 문자열 메소드다. 이 문자열 메소드는 객체의 속성으로 간주되기도 한다.
마침표/점이 있다고 해서 반드시 메소드라고 생각해서는 안된다.
반복가능 객체 vs 반복자
for 문에서 사용되기 위해서는 iterable object (반복가능한 객체)여야 한다.
반복 가능한 객체로는 range, list, tuple, string 같은 유형이 포함된다.
for 루프문에는 iter() 과 next() 를 호출한다.
반복 가능 객체는 파이썬에 내장된 iter()에 전달되며, 이 함수는 iterable object를 iterator object(반복자 객체)로 반환한다. 그후, next()에 전달되어 객체에 포함된 다음 원소를 반환한다.
| |
iter()은 __iter__을, next()는 __next__를 호출하기 때문에, 클래스 문에서 나만의 데이터 타입을 만들 때 이 던더 메소드들을 사용해서 특별한 메소드를 구현할 수 있다.
구문 에러 vs 런타임 에러 vs 의미 에러
구문 에러
지정된 프로그래밍 언어의 유효한 명령어에 대한 규칙에서 벗어나 잘못된 문법이나 단어들이 입력되었을 경우, 발생되는 에러
런타임 에러
실행 중인 프로그램이 존재하지 않는 파일을 열려고 하거나, 숫자를 0으로 나누는 것과 같은 몇 가지 작업을 수행하지 못 하는 경우에 발생한다.
의미 에러(semantic error)
에러 메세지를 발생하거나, 충돌을 일으키지 않지만 컴퓨터가 프로그래머의 의도한 방식으로 코드를 수행하지 않은 걸 말한다.
파라미터 vs 인수
parameter(파라미터) 는 def 문에서 괄호 사이의 변수 이름들을 말한다.
argument(인수) 는 함수 호출에서 전달된 값으로 파라미터에 지정된다.
| |
타입 강제변환 vs 타입 캐스팅
데이터 타입이 ‘명시적으로’ 변환되는 걸 객체를 casting 한다고 할 수 있다.
하지만, ‘묵시적으로’ 데이터 타입이 변환되는 거를 타입 강제변환(type coercion) 이라고 한다.
| |
프로퍼티(property) vs 속성(attribute)
속성은 객체와 연관된 이름이라는 걸 변수 vs 속성 편에서 알았다.
파이썬에서 property는 훨씬 더 깔끔한 구문으로 getter와 setter를 사용할 수 있는데, 이 getter와 setter란 속성에 값을 직접 대입하는 것 대신, 프로그램은 해당 속성에 대한 setter method를 사용하여 올바른 값만 할당하도록 한다. 그리고, getter method를 사용하여 속성의 값을 읽는다.
바이트 코드 vs 기계어 코드
소스 코드 – (컴파일) –> 기계어 코드: CPU의 명령어 집합
이 기계어 코드로 컴파일된 프로그램을 바이너리(binary) 라고 한다.
소스 코드를 기계어 코드로 바꾸는 방법에는 다른 방법이 있는데, 소스 코드를 기계어 코드로 만드는 대신 바이트 코드(bytecode)를 만들면 된다. 이 바이트 코드는 CPU가 직접 수행하는 게 아니라, 소프트웨어 인터프리터 프로그램이 수행한다.
파이썬 바이트코드는 실제 CPU가 수행하는 명령어가 아닌 파이썬 내부에서 자체적으로 해석해서 수행하는 명령어로 구성되어 있다. .py 소스 파일이 인터프리터로 넘어갈 때 생성되는 .pyc 파일에 저장된다. C로 작성된 C파이썬 인터프리터는 파이썬 소스 코드를 파이썬 바이트코드로 컴파일한 다음 해당 바이트 코드를 수행할 수 있다.
파이썬 인터프리터는 파이썬 소스 코드를 파이썬 바이트 코드로 컴파일한 다음, 해당 바이트 코드를 수행할 수 있다.
스크립트 vs 프로그램, 스크립트 언어 vs 프로그래밍 언어
스크립트와 프로그램을 구별하는 방법 중 하나는 바로 코드 실행 방식이다.
스크립트 언어로 작성된 스크립트는 소스 코드로부터 직접 해석되지만, 프로그래밍 언어로 작성된 프로그램은 바이너리로 컴파일 된다.
파이썬 프로그램이 실행될 때, 바이트 코드로 컴파일하는 단계가 있어도 컴파일 언어로 바라보지 않는다.
왜냐하면 언어는 컴파일이나 해석 관점이 아닌, 컴파일러나 인터프리터 구현체 관점으로 바라봐야하기 때문이다.
라이브러리 vs 프레임워크 vs SDK vs 엔진 vs API
라이브러리
제 3자가 만든 코드 모음의 총칭
프레임워크
제어 역전(inversion of control)로 동작하는 코드의 모음이다. 프레임워크의 요구에 따라 호출될 함수를 코드로 만든다.
SDK(Software Development Kit)
특정 운영체제나 플랫폼에서 동작하는 애플리케이션 작성을 돕는 코드 라이브러리, 문서화, 도구가 모두 포함된다.
엔진(engine)
개발자의 소프트웨어가 외부에서 제어할 수 있는 독립적으로 동작하는 대규모 시스템