0. Introduction
원티드 백엔드 챌린지 2월: MySQL ‘잘’ 사용하기 를 듣고 제 언어로 정리한 포스팅입니다.
해당 챌린지의 목표는 주니어 개발자 및 개발 준비생을 대상으로 하기 때문에, MySQL의 특징을 이해하여 효율적으로 사용하고, MySQL 기본 개념들을 학습하여 기술 면접에 대비하는 게 목적입니다.
그래서 운영체제의 cache 운용도가 높은 storage engine을 최적화할 때 어떻게 해야하는가 또는 쿼리 효율 개선 같은 내용은 다루지 않습니다.
해당 포스팅의 주제와 키워드
이번 포스팅의 주제는 [다양한 데이터베이스의 특징과 장단점] 입니다.
Keyword: 데이터 베이스의 원칙, CAP Theorem, RDBMS, NoSQL
기본 용어: Read / write / query / record & row
- record는 DB에 저장된 data를 의미
1. 데이터베이스의 원칙
무결성, 안전성, 확장성
아래 3가지를 고려하여 DB를 정해야 한다.
1.1 무결성(data integrity)
데이터가 전송, 저장, 처리되는 과정에서 변경되거나 손상되지 않아야한다는 원칙 -> 정확성, 일관성, 유효성을 유지
integrity 단어의 의미
integrity 단어는 말, 행동, 생각이 일치하여 일관되고, 이 생각을 기반으로 행동과 말이 온전한 상태라는 의미를 가진다.
그렇다면 DB에서의 integrity란?
데이터는 일관되어야 하고, 완전해야 하고, 손상되지 않고 정확해야 한다는 의미다.
그래서 데이터의 정확성, 일관성, 유효성 을 유지한다.
어떤 개발자가 동일한 데이터를 요청하면 동일한 값을 가진 데이터가 보내져야 한다.
1.2 안전성(data reliability)
데이터를 보호해야한다는 원칙
db를 복제하든지, stand-by db를 대기해둔다든지, 인증/인가되지 않은 사용자로부터 데이터를 보호 하는 걸 말한다.
1.3 확장성(scalability)
데이터 양이나 사용자가 늘어날 때 대비하기 위해 확장되는 성질
MySQL, Redis는 확장성이 좋지 않다.
2. 다양한 데이터베이스 종류: RDBMS vs NoSQL
- DB의 종류: RDBMS(MySQL, PostgreSQL..), NoSQL(redis, MongoDB)
- 서비스에 적합한 DB 선택법: CAP Theorem
2.1 RDBMS
Ex: MySQL, Oracle, PostgreSQL…
데이터를 row와 column으로 이뤄진 table의 형태 로 저장되기 때문에 데이터 무결성이 보장 된다. 그래서 만약 schema가 자주 변경되거나 column이 자주 변경되는 데이터는 RDBMS가 적합하지 않다.
그리고, 이 저장된 table로부터 SQL(Structured Query Language) 를 사용해서 데이터를 쉽게 읽어오거나 조작한다.
scale out이 아닌 scale up이 가능한 이유:
- 여러 db를 서버에 나눠서 저장해도 table name이 중복될 수 없기 때문에 scale up을 해야 한다. 하지만 이 특성으로 인해 분산 저장을 하지 않기 때문에 데이터 일관성이 잘 유지된다.
2.2 NoSQL
Ex: key-value, graph, document
데이터가 저장되는 형태인 key-value, graph, document 에 따라 NoSQL 여러 종류로 나눠진다.
데이터가 저장되는 형태는 더 많지만 위 3가지가 대부분이므로 더 알아보지 않는다.
2.2.1 key-value
- key-value 쌍으로 데이터가 저장된다.
- 여기서 Key는 unique identifier로 사용되기 때문에 key는 중복되지 않는다. 그래서 추가하면 기존에 있던 key는 날라간다.
- ex) redis, DynamoDB
[Redis]
- cache로 사용: 자주 사용되는 쿼리 명령어를 캐쉬에 저장하여 바로 사용
- docker나 쿠버네티스 상에 올릴 때 많이 사용
- celery와도 많이 사용하여 message broker로서 pub/subscribe 에 보내진다.
- ❗️한계: 위 3가지 DB 원칙 중 확장성의 관점에서는 redis는 in-memory 기반으로 최대 RAM 크기까지만 확장이 가능하기 때문이다.( not scalable )
[DynamoDB in AWS]
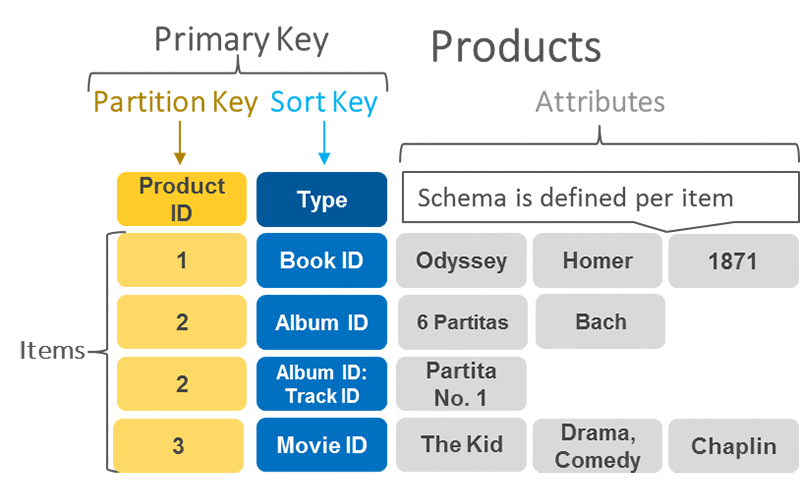
- 최근에 많이 사용되고 있다.
- redis와 달리 key가 partiton key(primary) 와 sort key(secondary, optional)로 나눠진다.
- partition key는 scale out으로 DB가 나눠졌을 때 값이 존재하는 위치를 나타낸다.
- 장점: scalable → HA(High Availability), serverless
2.2.2 graph
데이터가 graph 형태로 저장되기 때문에, SNS 등 관계가 복잡한 상황에서 자주 사용된다.
ex) instagram, linkedin
- 각 user를 node로 생각하고, node 간의 관계는 edge를 사용해서 나타낸다.
- 종류: Neo4j, OrientDB 등
2.2.3 document
데이터가 document 형태로 저장되서 구조가 자유롭다. ex) JSON 또는 XML 형태
MongoDB를 통해서 설명해보겠다.
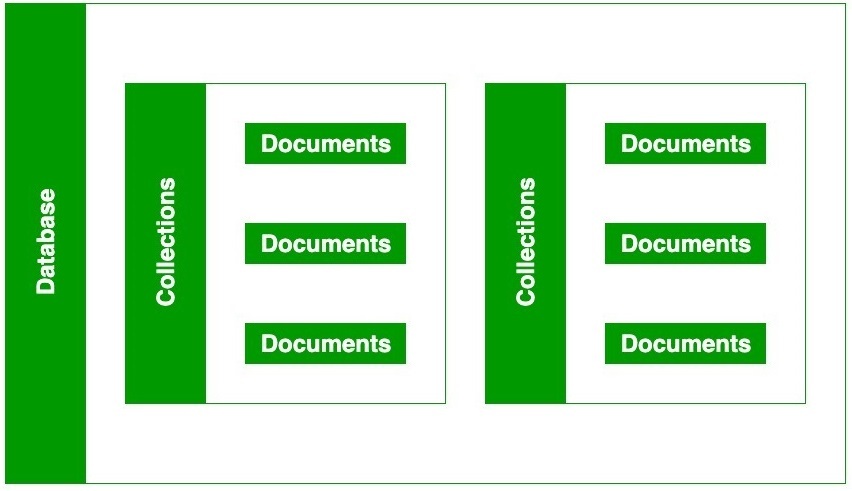
MySQL과 비교하자면 Collections이 table이고, Documents가 table의 row라고 생각하면 된다.
- 스키마를 만들 수 있지만, 형태가 스키마에서 떨어져도 자유롭게 저장할 수 있다.
- 그래서 이 DB는 블로그 같은 곳에 사용될 수 있다.
- DB 별로 데이터를 조작할 수 있는 언어가 따로 있다.
- 종류: MongoDB, CassandraDB, Couchbase 등이 해당
3. DB를 나누는 또 다른 기준: row oriented db vs column oriented db
DB를 나누는 또 다른 기준이 row-oriented 와 column-oriented가 있다.
row 와 column oriendtd에 따른 DB 종류
- row-oriented DB: MySQL, PostgreSQL, hbase
- column-oriented DB: CassandraDB, hbase, Bigquery
- big query: 구글에서 만든 DB 엔진
row와 column oriented에 따른 read, insert 성능 차이
| row oriented db | column oriented db | |
|---|---|---|
| read | 느림 | 빠름 |
| insert | 빠름 | 느림 |
가정
데이터가 아래 table처럼 저장되어 있다고 가정하자.
| Name | City | Age |
|---|---|---|
| James | Seoul | 29 |
| Kang | London | 33 |
| Mac | London | 27 |
3.1 Row oriented DB
column으로 스키마가 정해져서 row가 원하는 데이터인 DB
그러면 Row oriented DB에 대해 알아보자.
3.1.1 disk에 저장되는 형태
row oriented DB의 저장 형태는 대략적으로 다음과 같다.
table의 각 row들이 disk에 저장될 때 한 줄로 저장된다.
| James | Seoul | 29 | Kang | London | 33 | Mac | London | 27 |
disk의 block에는 다음과 같이 각 row 들로 저장된다.
block 1
Name City Age James Seoul 29 block 2
Name City Age Kang London 33 block 3
Name City Age Mac London 27
3.1.2 추가
row oriented db에서의 데이터 추가는 문제가 되지 않는다.
만약 row가 한 줄 추가된다면 table은 다음과 같이 한 줄 추가된다.
| Name | City | Age |
|---|---|---|
| James | Seoul | 29 |
| Kang | London | 33 |
| Mac | London | 27 |
| Paul | Chicago | 22 |
disk에는 다음과 같이 동일한 row의 맨 끝에 추가된다. 추가된 데이터는 bold 표시를 했다.
| James | Seoul | 29 | Kang | London | 33 | Mac | London | 27 | Paul | Chicago | 22 |
그래서 row oriented db에서의 데이터 추가는 간단하여 문제가 되지 않는다.
3.1.3 조회
조회하려는 속성 값에 대해 연속적으로 저장되지 않기 때문에 문제가 된다.
나이 관련된 데이터를 조회하고 싶을 때 row로 저장되기 때문에 나이 관련 데이터가 연속적이지 않아 조회하는 데 시간이 걸린다.
| James | Seoul | 29 | Kang | London | 33 | Mac | London | 27 |Paul | Chicago | 22 |
그래서 id가 auto increment여도 순서가 보장되지 않기 때문에 이를 위해서 row 기반 DB에서는 별도의 index 테이블을 사용한다.
🔆 즉, row oriented db에서의 최적화란 read를 어떻게 빠르게 할 것인가를 의미한다.
3.1.4 삭제 후 추가
데이터 삭제하여 생긴 빈 자리에 그대로 추가되기 때문에 데이터 순서가 보장되지 않는다. 그래서 DB에서는 ‘인덱스’라는 걸 생성하여 관리한다.
현재 table이 다음과 같다고 가정하자.
| Name | City | Age |
|---|---|---|
| James | Seoul | 29 |
| Kang | London | 33 |
| Mac | London | 27 |
| Paul | Chicago | 22 |
disk에는 다음과 같이 같이 한 줄로 이어서 저장되어 있다.
- | James | Seoul | 29 | Kang | London | 33 | Mac | London | 27 | Paul | Chicago | 22 |
이런 상황에서 | Mac | London | 27 | 데이터가 삭제된다면 디스크에서는 어떻게 될까?
- | James | Seoul | 29 | Kang | London | 33 | | | ___ | Paul | Chicago | 22 |
위와 같이 빈 자리가 생긴다.
그 다음 다른 데이터 | Mike | Shanghai | 43 | 이 추가되면 디스크에는 어떻게 저장되는 것일까?
뒤에 있는 | Paul | Chicago | 22 | 이 댕겨지면서 뒤에 저장될까? 아니면 빈 자리에 데이터가 그대로 추가될까?
바로 후자다.
그래서 row oriented db 는 db에 저장되는 순서를 보장하지 않는다. 이 특성으로 인해서 ORDER BY 로 정렬할 때, id의 경우 DB에서 별도로 인덱스라는 걸 생성하여 관리한다고 한다.
❗️추가할 때, 빈 자리로 데이터를 shift하면 순서가 맞혀지지 않을까?
이럴 경우, shift하는데 시간이 많이 걸리기 때문에 빈 자리에 바로 추가하는 게 낫다.
3.2 Column oriented DB
row으로 스키마가 정해져서 column이 원하는 데이터인 DB
3.2.1 disk에 저장되는 형태
그리고, disk에는 다음과 같이 저장된다.
block 1
Name James Kang Mac block 2
City Seoul London London block 3
Age 29 33 27
3.2.2 추가
row 기반 db처럼 끝에 추가되는 게 아닌 ‘데이터 사이에 추가 ’ 되는 거라 오래 걸린다.
추가 되기 전 디스크에 저장된 형태는 다음과 같다.
- | James | Kang| Mac | Seoul | London | London | 29 | 33 | 27 |
데이터가 추가되면 아래와 같은 순서로 데이터가 저장된다. 추가된 데이터는 bold 처리했다.
- | James | Kang| Mac | Paul | Seoul | London | London | Chicago | 29 | 33 | 27 | 22 |
저장된 데이터의 순서를 보면 row oriented db와 달리 어떻게 저장되는지 이해할 수 있다.
3.2.3 조회
만약 내가 Age를 기준으로 데이터를 찾는다고 하면 row oriented db와 달리 조회하는 게 쉽다. 왜냐하면 아래와 같이 한 가지 column에 대해 한 디스크 위치에 저장되어 있기 때문이다.
bold 처리된 게 나이 관련 데이터다.
- | James | Kang| Mac |Paul | Seoul | London | London |Chicago | 29 | 33| 27 | 22 |
그래서 bigquery가 데이터 조회에서 MySQL보다 빠른 이유가 바로 이 때문이다.
4. 서비스에 적합한 데이터베이스 선택법
4.1 CAP Theorem

consistency(일관성)
- 데이터베이스가 서버가 여러 개인 분산 데이터베이스 상에서 모든 node들이 데이터베이스 안에 같은 값을 가지고 있어야 하는 성질 (같은 정보를 공유하고 있어야하는 성질)
- 어떤 노드에게 요청을 보내도 상관없이 같은 데이터를 보여준다.
- 하지만 request를 보내면 동기화를 위해서 해당 request가 delay 될 수 있다.
- 그래서 일관성의 목표는 데이터의 동기화가 충분히 빨라서 사용 상 문제가 없도록 하는 것이다.
- 금융 쪽에서는 이 일관성이 중요하다.
- 송금 데이터가 데이터베이스 노드당 동기화되지 않으면 송금 안된 줄 알고 계속 보낸다.
- 실생활에서 예시: 통신사 상담원에게 전화하여 집 주소를 변경하고 전화를 끊은 뒤 집 주소 중 일부가 잘못 전달된 걸 알고, 다시 전화하여 다른 상담원이 받을 지라도 변경된 내용을 정확히 알고 있는 상황
availability(가용성)
- 데이터베이스에 보내는 모든 request는 response를 반드시 받아야 하는 성질로, 시스템이 중단되는 일 없이 언제든지 사용 가능한 상태여야 한다.
- 작업이 실패하더라도 사용자는 응답을 받을 수 있어야 한다.
- consistency는 동기화 때문에 response가 바로 안온다.
- 하지만 해당 response가 가장 최근 데이터라는 것을 보장받을 수 없다. 데이터가 일관되지 않아도 언제든지 접근할 수 있다.
- 접근하는 node에 따라 값이 다르다
- E-commerce에서 중요
- 실생활에서 예시: 24시간 가능한 통신사 고객센터
partition-tolerance(분할 허용성)
- DB node 간 소통이 불가능 하더라도 서비스는 정상적으로 작동하는 성질
- 데이터량이 매우 많을 때 중요
- 인스타그램 같은 SNS에서 중요
- 실생활에서 예시: 통신사 고객센터에 전화하여 문의를 하니 고객센터에서는 현재 본사와 통신할 수 없다고 한다. 하지만 고객센터는 정상적으로 운영된다.
4.2 위 3가지를 다 가질 수 없는 이유
서버가 s1과 s2로 나눠져 있는 상황이라고 하자.
partition-tolerance가 없으면??
consistency, availability 함께 지원된다.
- 이 s1과 s2 사이에서 소통할 수가 없어서 데이터를 분산 저장할 수 없다.
- 그러면 한 서버로만 흘러가서 write / read를 수행하기 때문에 request를 보내면 바로 response를 받을 수 있고, 항상 동일한 데이터를 얻을 수 있다.
partition-tolerance가 있으면?
consistency와 availability는 함께 지원되지 않는다.
서버가 끊겨도 계속해서 소통할 수 있다면?
db가 consistency하다면 db에 요청을 보냈을 때, s1과 s2의 각 서버가 동기화 작업을 하느라 response가 느려지고, 사용자는 계속 기다려야 한다.
- 쿠팡에서 탄산수를 주문했는데 바로 response가 오지 않는다. 왜냐하면 다른 서버에도 저장을 해야하기 때문이다.
하지만 db가 consistency하지 않고, 데이터가 availability 하다면 write/read request를 했을 때 바로 response가 온다. 대신에 write한 데이터가 모든 서버에 동기화되지 않기 때문에, 어느 서버로 흘러가냐에 따라서 내가 요청한 write data가 안올 수 있다.
4.3 예시
RDBMS
RDBMS: Netflix (ex: MySQL)
- 영상에 대한 정보를 저장하는 방식
- 데이터 분산은 잘 안되서 내가 write한 걸 잘 읽어올 수 있다.
NoSQL
NoSQL: 인스타그램
인스타그램은 availability를 굉장히 중요하게 생각한다.
- 즉, 데이터가 write된 게 매우 중요하게 여겨서, 해당 사용자가 속한 노드에서 이 데이터가 저장되었는지가 중요하다. 왜냐하면 글이나 메세지는 작성된 게 남겨져야하기 때문이다.
그리고 consistency를 중요하게 여기지 않는다.
- 즉, 저장된 데이터가 다른 노드들에 복제되었는지는 그리 중요하지 않아서, 동기화를 바로 하지 않고 나중에 할 시간이 별도로 있다.
그래서 각 도메인과 데이터 종류에 따라서 DB 선택을 잘 해야 한다.
5. RDBMS와 NoSQL 비교
| RDBMS | NoSQL | |
|---|---|---|
| Data modeling 특징 1 | 스키마에 맞춰서 관리하기 때문에 데이터 정합성 보장 | 자유롭게 데이터를 관리할 수 있다. |
| 어느 data가 해당 | 관계를 맺고 있는 데이터가 자주 변경되는 경우 해당 | 데이터 구조를 정확히 알 수 없고, 데이터가 변경/확장 되는 경우 해당 |
| Scalability | Scale up | Scale out |
| Query Language | SQL(Structured Query Language) | 문법이 조금 다름 |
| Consistency | Strong | eventual consistency |
| flexibility | Not really | very flexible |
위 데이터 종류에 맞춰서 분리 적용한다.
- 사용자 정보의 경우 스키마가 변하지 않기 때문에 RDBMS를 사용한다.
RDBMS는 scale out이 어려운 이유
RDBMS는 위에서 언급한 대로 스키마에 맞춰서 데이터가 저장되기 때문에 중복이 어렵다. 이는 다르게 말하자면 테이블 간에 column을 통한 관계 형성이라는 제약 조건을 통해서 이뤄지고 있다. (그래서 데이터 모델링이 RDBMS에서는 중요하다.)
그래서 이런 제약조건을 모두 만족하면서 분류하여 나눠서 확장을 해야하므로 Nosql보다 더 어렵다. nosql은 각 객체를 분류하는 기준이 강하지 않기 때문이다. 즉 중복을 줄이기 위한 “관계” 로 인해서 확장하기가 어렵다.
🔆 Scale up VS. Scale out

- scale out의 단점: 데이터가 중복될 수 있다.