0. Introduction
원티드 백엔드 챌린지 2월: MySQL ‘잘’ 사용하기 를 듣고 정리한 포스팅입니다.
해당 챌린지의 목표는 주니어 개발자 및 개발 준비생을 대상으로 하기 때문에, MySQL의 특징을 이해하여 효율적으로 사용하고, MySQL 기본 개념들을 학습하여 기술 면접에 대비하는 게 목적입니다.
그래서 운영체제의 cache 운용도가 높은 storage engine을 최적화할 때 어떻게 해야하는가 또는 쿼리 효율 개선 같은 내용은 다루지 않습니다.
해당 포스팅의 주제와 키워드
이번 포스팅의 주제는 [Big Tech가 MySQL을 선택하는 이유] 입니다.
Keyword: Transaction, Database Lock, Isolation Level
MySQL installation
Mac에서 MySQL 설치는 해당 문서 How to Install MySQL 8 on macOS Using Homebrew를 참고하자.
MySQL 로그인
- root 모드:
mysql -u root -p
1. MySQL을 사용하는 BigTech와 이유
MySQL을 사용하는 BigTech
Uber, Airbnb, Pinterest, Netflix, Twitter, Amazon, Udemy, Slack
MySQL을 사용하는 이유
transaction을 요구할 때 에러없이 넣고 싶으면 RDBMS를 사용
오픈 소스
2. MySQL storage engine
데이터 읽기/쓰기를 담당하며, 어떤 스토리지 엔진을 사용하느냐에 따라서 MySQL에 데이터를 읽고 쓰는 방법이 다름
2.1 Engine의 종류
MySQL 엔진은 크게 SQL 엔진과 Storage 엔진으로 나눠진다.
SQL engine의 역할
query parsing
- ORM 사용 시 이 기능을 통해서 SQL 문법으로 바꿔주는 역할
query optimizing
- 쿼리를 실행하면 ‘실행계획’이라는 걸 가지고서 DB가 최적화를 스스로 고민 후 실행한다. 그러면 storage engine이 실행된 SQL을 바탕으로 데이터를 가져온다.
query 실행
더 상세한 Engine 종류는 MySQL 설치 및 실행 후 SHOW ENGINES을 입력하면 된다.

2.2 중요한 Storage engines
위 이미지에 있는 ENGINE을 지금 단계에서는 다 알기보다는 아래 3가지만 알고 있자.
- MyISAM
- MEMORY
- InnoDB (제일 중요)
- 요즘은 innoDB가 default
- create table을 할 때 별도로 지정해주지 않는다면 default engine이 사용
❗️ MEMORY ENGINE의 경우, memory에 저장되어 cache로 사용되는데 이 ENGINE을 사용하기보다는 redis를 사용해보자. (이런 게 있다 정도로만 알고 있자.)
InnoDB의 장점
버퍼링
- read는 foreground thread를, write는 background thread를 사용한다. 그래서 thread pool에 한계가 있어서 모아서 진행해서 효율을 높이는 기능
Foreign key
transaction
- InnoDB만 transaction을 지원한다.
- InnoDB 때문에 MySQL에서도 postgreSQL처럼 transaction이 가능하다.
3. 🔆 Transaction
사용자의 작업셋을 ‘모두 완벽하게 처리’ 하거나 ‘처리하지 못하면 원상태로 복구’ 하여 작업의 완전성을 보장하는 하나의 논리적인 작업 단위
그러면 MySQL InnoDB가 지원하는 transaction에 대해 눈으로 직접 확인해보자.
🔆 서버 개발자들은 직접 db에 접근하지 않고 흔히들 ORM을 사용한다. 각 프레임워크에서는 각 ORM별로 트랜젝션을 지원하는 쿼리가 존재하기 때문에 사용해봐야 한다.
3.1 트랜잭션의 특징 ACID
Atomicity(원자성)
한 트랜잭션의 연산들이 모두 성공하거나, 반대로 전부 실패되는 성질
A 계좌에서 B 계좌로 돈 500만원을 입금한다고 하자. A 계좌의 현재 잔액은 1000만원, B 계좌의 현재 잔액은 0원이다.
- 첫 번째, A 계좌의 잔액 1000만원을 500만원으로 수정한다.
- 두 번째, B 계좌에 잔액 0원을 500만원으로 수정한다.
성공적으로 수행된다면 A, B 각 계좌에는 500만원이 남는다.
하지만 일부만 적용된다면 예를 들어 만약 첫 번째 과정만 수행되고, 두 번째 과정이 실패된다면 A 계좌의 500만원은 세상에서 사라지는 돈이 된다. 그러므로 한 가지라도 실패한다면 모든 작업이 실패로 돌아가야 한다. 이것이 원자성이다.
Consistency(일관성)
허용된 방식으로만 데이터를 수정해야 한다.
데이터베이스의 모든 데이터는 여러 가지 조건, 규칙에 따라 유효해야 한다.
예를 들어 A한테 500만원이 있고, B는 0원을 가지고 있다. A는 B에게 최대 500만원을 송금할 수 있다. 하지만, B는 어떤 돈도 송금할 수 없다. 0원이기 떄문이다. 만약 돈을 송금할 수 있다면 해당 데이터는 유효하지 않다.
Isolation(고립)
트랜잭션 수행 시 서로 끼어들지 못한다.
복수의 병렬 트랜잭션은 서로 격리되어 마치 순차적으로 실행되는 것처럼 작동되어야 하고, 여러 사용자가 같은 데이터에 접근할 수 있어야 한다.
하지만 순차적으로 접근이 가능하다면 성능이 떨어진다.
Durability(지속성)
성공적으로 수행된 트랜잭션은 영원히 반영되어야 한다.
3.2 트랜젝션을 지원하는 스토리지 엔진(InnoDB)와 트랜젝션을 지원하지 않는 스토리지 엔진(MyISAM) 비교
1) Engine이 다른 table 생성하기
엔진 설정이 각각 InnoDB고 MyISAM인 table을 생성해보자.
SHOW databases를 사용하여 databases 목록을 확인하고, 사용할 database를use <database name>을 사용하여 database를 바꾼다.ENGINE이 MyISAM인 DB
CREATE TABLE myisam (id INT NOT NULL, PRIMARY KEY(id)) ENGINE=MyISAM;
ENGINE이 InnoDB인 DB
CREATE TABLE innodb (id INT NOT NULL, PRIMARY KEY(id));- default이므로 따로 ENGINE을 입력하지 않아도 된다.
생성된 table 보기:
SHOW CREATE TABLE <생성된 table 이름>
2) 정수 5 data 추가하기
desc <table name>;으로 구조를 출력할 수 있다.
myisam에 데이터를 추가한다.
INSERT INTO myisam (id) VALUES (5);SELECT * FROM myisam으로 table 데이터를 확인한다.
innodb table에 데이터를 추가한다.
INSERT INTO innodb (id) VALUES (5);SELECT * FROM innodb으로 table 데이터를 확인한다.
3) 정수 1부터 5까지 data 추가해보기
- myisam에 추가:
INSERT INTO myisam (id) VALUES (1), (2), (3), (4), (5);- 실행 결과:
Duplicate entry '5' for key 'myisam.PRIMARY'
- 실행 결과:
- innodb에 추가:
INSERT INTO innodb (id) VALUES (1), (2), (3), (4), (5);- 실행 결과:
Duplicate entry '5' for key 'innodb.PRIMARY'
- 실행 결과:
4) 실행 결과 확인해보기
myisam 확인해보기:
SELECT * FROM myisamid 1 2 3 4 5 innodb 확인해보기:
SELECT * FROM innodbid 5 🔆 innodb는 트랜젝션을 지원하기 때문에 한 가지 작업이라도 에러가 발생되어 처리되지 못하자 원상태 그대로를 유지한다. 이것이 바로 Transaction 이다.
3.3 어떻게 가능한 걸까?
‘Buffer pool’ 과 ‘Undo log’ 를 사용한다.
- Buffer pool: 일괄적으로 모아서 처리하는 공간
- Undo log: error가 발생되면 되돌리기 위해 데이터를 임시로 저장하는 공간
테이블의 데이터를 변경하는 작업을 하기 전에 다음 작업들이 일어난다.
위에서 정수 1부터 5까지를 추가하는 명령어를 실행했었다.
- disk에는 id가 5인 값이 저장되어 있는 상태였다.
- 명령어를 실행하면 Buffer pool에 먼저 id가 1부터 5인 값이 생성된다.
- Undo log에는 1)번 상태를 기억해두고 있다.
- 2)번에서 buffer pool에서 생성한 데이터를 하나씩 disk에 추가한다.
- 4)번 과정에서 error가 발생되면 3)번에서 기억해둔 데이터를 disk로 가져와 복귀시킨다.
3.4 Transaction - states

transaction에도 상태(state)가 존재한다.
3.2 어떻게 가능한 걸까? 에서의 각 과정은 다음과 같이 진행된다.
- Active state -> Partially commited state -> Failed state -> Aborted state -> Terminated state
만약 성공적으로 흘러가면 다음과 같이 진행된다.
- Active state -> Partially committed state -> Commited state -> Terminated state
4. Database Lock
하나의 데이터를 동시에 여러 명이 조작할 수 없도록 데이터를 잠궈서 동시성을 보장하는 기능
[Lock의 종류: MySQL engine lock vs InnoDB lock]
- SQL 엔진이 제공하는 lock: global lock, table lock, named lock, meta-data lock
- MySQL의 InnoDB가 제공하는 lock: record lock, Auto increment Lock 등등
위 Lock의 종류들은 다 MySQL이 알아서 Lock을 걸고 풀기 때문에 잘 사용되지 않는다.
DEAD LOCK
한 곳에서만 자원에 접근이 가능하고, 다른 곳들로부터 자원에 접근하는 걸 막은 걸 ‘DEAD LOCK’이라 한다.
만약 이 상황에 계속해서 지속되면 좋지 못한 상황이기 때문에 innoDB에서는 이 같은 Lock을 따로 관리리하는 table이 존재한다.
4.1 글로벌 락(Global lock)
범위가 가장 넓은 lock으로서, 서버 전체에 영향을 미치기 때문에 A 서버에서 global lock을 걸면 B 서버에까지 적용된다.
잘 사용되지 않는다.
Global lock 걸기:
FLUSH TABLES WITH READ LOCK;Global lock을 해제하기: Global lock을 걸은 서버에서 MySQL과의 연결이 끊겨야 해제
SELECT를 제외한 모든 쿼리들이 대기상태로 남기 때문에, 쿼리를 입력해도 진행이 되지 않는다.서버 전체에 영향을 미치기 때문에 작업 대상이나 테이블이 다르더라도 동일하게 영향 받는다.
- table이
myisam상태에서 global lock을 걸면innoDB에 있는 서버도 락이 걸린다.
- table이
4.2 Table Lock
특정 테이블에 대한 lock으로서 read lock과 write lock으로 나눠진다.
read lock: READ 작업만 가능하도록 잠그는 기능
LOCK TABLES innodb READ;
write lock: WRITE 작업만 가능하도록 잠그는 기능
LOCK TABLES innodb WRITE;
lock을 걸지 않으면 DB를 read 또는 write하기 직전에 data가 바뀔 수 있기 때문이다.
해당 명령어를 사용할 일은 거의 없다. 그 이유는 특별한 상황이 아니라면 다른 작업에 영향을 미치기 때문이다.
테이블에 데이터를 변경하는 쿼리를 실행하면 자동으로 lock이 발생한다.
- 데이터 추가, 변경 시 lock 설정
- 데이터 변경 commit 시 lock release
- InnoDB의 경우에는 DML 쿼리에서는 lock이 작동하지 않과 DDL의 경우에만 영향을 미침
- 스토리지 엔진의 구조 차이라는 정도만 알아두자.
READ LOCK test
한 터미널에서 READ LOCK test 해보기
- READ LOCK 걸기:
LOCK TABLES innodb READ;
- READ LOCK 걸기:
- UPDATE 작업 실행:
INSERT INTO innodb (id) VALUES (34);
- UPDATE 작업 실행:
- 실행 결과:
ERROR 1099 (HY000): Table 'innodb' was locked with a READ lock and can't be updated
- 실행 결과:
- READ LOCK 풀기:
UNLOCK TABLES;
- READ LOCK 풀기:
- UPDATE 작업 실행 완료
두 터미널(A, B)에서 READ LOCK test 해보기
- A terminal에서 innodb에 대해 READ LOCK을 걸어보자.
- B termianl에서 UPDATE 작업 실행:
INSERT INTO innodb (id) values (98);
- B termianl에서 UPDATE 작업 실행:
- 결과: 쿼리문이 진행되지 않는다.

- A terminal에서 READ LOCK을 풀어보자:
UNLOCK TABLES;
- A terminal에서 READ LOCK을 풀어보자:
- 대기되고 있던 UPDATE SQL이 바로 진행된다.

WRITE LOCK test
- 두 터미널(A, B)에서 READ LOCK test 해보기
- Temianl A:
LOCK TABLES innodb WRITE;실행
- Temianl A:
- Terminal B:
SELECT * FROM innodb;를 입력하면 실행되지 않고 LOCK에 걸린다.
- Terminal B:
- Terminal A:
UNLOCK TABLES;실행
- Terminal A:
- Terminal B: 2)번에 명령어 바로 실행
4.3 Named Lock
GET_LOCK()이라는 명령어로 임의의 문자열에 대해 잠금을 설정하는 LockCOMMIT후SELECT RELEASE_LOCK(문자열)을 입력하여 Lock이 해제된다.- 자주 안사용한다.
- 여러 클라이언트가 상호 동기화를 처리해야할 때 사용할 수 있다.
- 많은 레코드에 대해 복잡한 요건으로 변경하는 트랜잭션에 유용하다.
❗️ MySQL에서는 autocommit이란 전역 변수가 참으로 되어 있어서 COMMIT 이 자동적으로 된다. 이를 확인하기 위해서는 SET GLOBAL VARIABLES LIKE 'autocommi';를 입력하면 확인할 수 있고, AUTO COMMIT을 끄고 싶으면 SET GLOBAL autocommit=0;을 입력한다.
Lock test
A, B termianl에서 test 진행
- Terminal A:
SELECT GET_LOCK('wanted', 30);
30분 동안 wanted 라는 문자열에 대해 사용하는 걸 잠금한다.
결과: True
GET_LOCK(‘wanted’, 30) 1 SELECT IS_FREE_LOCK('wanted');: 를 실행하여 LOCK이 자유로운지 확인하면 다음과 같은 결과가 뜬다. 0은 False를 의미하므로 Lock 걸려있다는 상태를 말한다.| IS_FREE_LOCK('wanted') | | ---- | |0 |
- Terminal A:
- Terminal B:
SELECT GET_LOCK('wanted', 20);
- 이미 A terminal에서 잠궜기 때문에 위 명령어는 잠겨져 대기하게 된다.
- Terminal B:
- Terminal A:
SELECT RELEASE_LOCK('wanted');를 실행하면 Lock이 풀리면서 2)번 명령이 실행될 수 있다.
- Terminal A:
4.4 메타데이터 락
데이터베이스 객체(table, column)의 이름이나 구조를 변경하는 경우에 사용되는 락
테이블 락처럼 별도의 명령어를 사용할 수는 없고, 테이블을 변경하는 등의 작업을 할 때 자동으로 가져왔다가 release한다.
이는 다른 락과 달리 명령어가 없어서 직접 보여줄 수 없으니 이런 게 존재하는 것만 알고 있자.
4.5 레코드 락
- 입력한 쿼리에 해당되는 record / row를 가져오는 동안 이 record / row에 lock을 거는 것
EXPLAIN SELECT * FROM innodb;: 해당 쿼리를 설명하는 테이블을 가져온다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | innodb | NULL | index | NULL | PRIMARY | 4 | NULL | 2 | 100.00 | Using index |
여기서 rows column에서 2라고 나와있는데, 위 쿼리로 데이터를 가져오는 동안 2개의 row에 record lock을 거는 것
만약 이게 8만개라면? 8만개의 row가 record lock에 걸린 것이므로 효율적이지 않다. 그래서 ‘인덱스’를 잘 설계해야 한다.
4.6 Auto Increment Lock
PRIMARY KEY의 중복 방지를 위해 table 생성 시 입력하는 auto increment에 거는 lock을 말한다.
row 추가 시 id 값이 자동적으로 증가하는 설정인 AUTO_INCREMENT에 대해 lock을 거는 것이다.
만약 row가 1개 밖에 없는 상황에서 여러 클라이언트가 데이터를 추가할 때, id = 2인 row가 여러 개가 생성될 수 있다. 그래서 innoDB가 동시에 데이터를 못 넣어 중복을 방지하고자 사용하는 게 auto increment lock이다.
매우 빨라서 체감하기 어렵다.
5. Isolation Level(격리수준)
여러 트랜잭션이 동시에 처리될 때 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있게 허용할지 말지 결정한다.
🔆 격리 수준의 종류에는 무엇이 있고, 각 격리 수준은 무엇이며 장단점은 뭔지, 그래서 무엇을 사용하면 좋은지에 대해서만 먼저 알고 있자.
- 격리 수준의 종류: 각 격리 수준마다 단점이 존재하는데 이 모든 걸 다 해결하는 방법은 default engine인 innoDB를 사용하는 것
- read uncommitted
- read committed
- repeatable read: 나머지는 이런 게 있다는 정도로만 알고, 이를 자세히 알자.
- serializable
❗️ 격리 기본 수준 값을 변경 시, 트랜잭션이 진행 중이라 바꿀 수 없다는 Error가 발생했다면 COMMIT을 사용하라.
❗️ autocommit = 1 이어도 start transcation으로 트랜잭션을 명시적으로 시작해주면 commit 명령어를 입력해야 DB에 적용이 된다.
❗️ mysql에서 나갔다가 다시 들어오면 autocommit은 다시 1로 세팅된다.
격리수준 별 발생할 수 있는 문제점
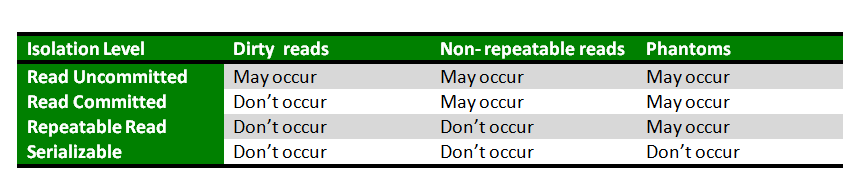
dirty read
한 트랜젝션에서 커밋 전 ‘데이터를 업데이트한 시점’을 기준으로 다른 트랜젝션에서 조회되는 데이터가 달라진다. 즉, 나의 transaction이 아닌데도 COMMIT 전 데이터가 읽혀서 데이터 정합성이 준수되지 않는 현상(reads are not consistent)이다. 데이터가 업데이트된 트랜잭션이 rollback되어도 다른 트랜잭션에서 이 데이터를 읽고 진행했기 때문에, 취소된 데이터가 남아 있어서 에러가 발생할 수 있다.
non-repeatable read
트랜잭션이 완료되지 않고 커밋된 데이터를 다른 트랜잭션에서 읽을 수 있어서 한 트랜잭션 내에서 동일한 쿼리를 2번 이상 보냈을 때 해당 조회 결과가 달라서 데이터 정합성이 준수되지 않는 현상을 말한다. 이 또한 dirty read와 유사하게 부분적으로 커밋된 트랜잭션이 rollback되어도 다른 트랜잭션에서 이 데이터를 읽고 진행했기 때문에, 취소된 데이터가 남아 있어서 에러가 발생할 수 있다.
- 만약 핀테크라면 금액이 달라지는 문제이기 때문에 심각하다.
phantom read
non-repeatable read는 한 row에 관한 것이고 phantom read는 여러 row 조회에 관한 것만 다르고 나머지는 동일하다.
5.1 Read uncommitted
COMMIT 되지 않은 데이터를 읽을 수 있는 격리 수준으로, 한 트랜잭션에서 다른 트랜잭션의 커밋되지 않은 데이터를 읽을 수 있기 때문에 이런 데이터는 변경될 수 있어서 ‘dirty read’라는 문제가 발생된다.
실습
- autocommit을 off 시킨다:
SET GLOBAL autocommit=0;- 결과 확인:
SHOW GLOBAL VARIABLES LIKE 'autocommit'; - 실제 작업할 때는 건드리지 않는다.
- 결과 확인:
- 기본 isolation level 값을 A, B terminal에서 모두 변경:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; - A, B terminal에서 모두 트랜젝션 시작:
START TRANSACTION;- 변경된 isolation level을 mysql 8.0 부터는 확인할 수 없다.
- TABLE 새로 생성:
CREATE TABLE auto (id INT NOT_NULL AUTO_INCREMENT, name VAR(4), PRIMARY_KEY(id)); - A, B terminal에서 모두 트랜젝션 시작:
START TRANSACTION - A terminal에서 데이터 추가:
INSERT INTO auto (name) VALUES ('jeha');- 현재 나의 transaction이므로 추가된 데이터가 보인다.
- B terminal에서 확인하기:
SELECT * FROM auto;- 다른 transaction인데 commit되지 않은 추가된 데이터가 보인다.
- ROLLBACK을 진행하여 TRANSACTION 취소:
ROLLBACK; - A terminal:
SELECT * FROM auto;-> commit을 실행하여 TRANSACTION을 마무리:COMMIT;- 취소된 데이터를 확인할 수 없다.
A terminal에 트랜젝션 과정 중에 데이터를 추가한 6번을 기준으로, B terminal에서 진행되는 트랜젝션 과정에서 조회되는 데이터가 달라진다.
한 트랜젝션 과정에서 데이터의 정합성이 보장되지 못하는 문제점이 발생된다. 또한 이로 인해서 여러 문제점이 발생될 것이다.
5.2 Read committed
COMMIT된 것만 읽을 수 있는 격리 수준으로 트랜젝션이 완료된 데이터만 다른 트랜잭션에서 조회 가능하다. dirty read는 발생하지 않고 non-repeatable read와 phantom read가 발생할 수 있다.
PostgreSQL의 기본값이다.
커밋되기 전에는 undo log에 있는 곳의 데이터를 읽어오므로 추가한 값이 없고, 커밋 후에 불러오면 추가한 값이 존재한다.
- undo log: 뭔가 잘못되면 돌려야돼서 임시로 저장하는 공간
- 데이터 업데이트 sql을 입력하면 이 sql을 table에 적용하기 전에 undo log에 현 상태를 임시 저장한 후 sql을 적용한다.
- 그 후 커밋이 안되어있으면 데이터를 가져올 때 undo log에 있는 데이터를 조회한다.
실습
- autocommit을 off 시킨다:
SET GLOBAL autocommit=0;- 결과 확인:
SHOW GLOBAL VARIABLES LIKE 'autocommit'; - 실제 작업할 때는 건드리지 않는다.
- 결과 확인:
- 기본 isolation level 값을 A, B terminal에서 모두 변경:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;- 변경된 isolation level을 mysql 8.0 부터는 확인할 수 없다.
- A, B terminal에서 모두 트랜젝션 시작:
START TRANSACTION; - 데이터 추가 전 데이터 조회 in A, B terminal:
SELECT * FROM auto; - A terminal에서 데이터 변경 후 확인:
UPDATE auto SET name='kim' WHERE name='lee'->SELECT * FROM auto;- 데이터 변경이 진행된 동일한 트랜젝션이므로 확인할 수 있다.
- B terminal에서 데이터 조회:
SELECT * FROM auto;- 변경 전 데이터로 조회된다.
- A terminal에서 commit 실행:
COMMIT; - B terminal에서 데이터 조회:
SELECT * FROM auto;- 변경 후 데이터로 조회된다.
- B terminal에서 commit 실행:
COMMIT;
READ UNCOMMITED와의 차이점을 확인했고, 문제점도 확인했다.
7)번 단계를 기준으로 B terminal에서 transaction이 진행 중인데 조회되는 데이터가 달라졌다. 이 부분이 transaction 진행 중에 데이터의 정합성이 보장되어야하는데 그러지 못하는 문제점이다.
5.3 🔆 Repeatable read
커밋 완료된 데이터에 대해서만 조회할 수 있으며 반복해서 행을 조회하더라도 똑같은 행을 보장하는 수준이다. 하나의 트랜잭션이 수정한 행을 다른 트랜잭션이 수정할 수 없도록 막아주지만 새로운 행을 추가하는 것은 막지 않는다. 그래서 똑같은 범위 쿼리를 실행해도 이후에 추가된 행이 발견될 수 있다. 그래서 ‘phantom read’가 발생할 수 있다. 그리고 InnoDB의 기본 Isolation level 값이다.
반복적으로 읽을 수 있다. 또한 undo 영역에 백업된 이전 데이터를 이용해서 동일 트랜잭션에서는 같은 내용을 보여줄 수 있도록 한다.
- undo record에는 lock을 걸 수 없어서 같은 트랜잭션에서 조회 가능
- 귀신 같이 row가 추가되어 이를 phantom 이라 한다.
❗️ non repeatable read와 헷갈릴 수 있다. 하지만 repeatable read는 한 행에 대한 것이고 phantom read는 전체 데이터에 관한 현상을 말한다.
phantom read에 대한 해결책
InnoDB에서는 undo log를 transaction-id을 기준으로 버전관리를 하여, 해당 transaction-id가 끝날 때까지 보관하기 때문에 phantom read가 문제가 되지 않는다.
그래서 innoDB를 default engine으로 계속해서 사용한다.
실습
- autocommit을 off 시킨다:
SET GLOBAL autocommit=0;- 결과 확인:
SHOW GLOBAL VARIABLES LIKE 'autocommit'; - 실제 작업할 때는 건드리지 않는다.
- 결과 확인:
- 기본 isolation level 값을 A, B terminal에서 모두 변경:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;- 변경된 isolation level을 mysql 8.0 부터는 확인할 수 없다.
- A, B terminal에서 모두 트랜젝션 시작:
START TRANSACTION; - 데이터 추가 전 데이터 조회 in A, B terminal:
SELECT * FROM auto; - A terminal에서 데이터 변경:
UPDATE auto SET name='lee' WHERE name='kim'; - B terminal에서 데이터 조회: 4번과 동일한 데이터가 조회된다.
- read uncommited라면 5번을 기준으로 B terminal에서 조회되는 데이터가 달라지만, 그렇지 않았다.
- A terminal에서 commit:
COMMIT; - B terminal에서 데이터 조회: 4번과 동일한 데이터가 조회된다.
- read commited라면 7번을 기준으로 B terminal에서 조회되는 데이터가 달라지만, 그렇지 않았다.
- B terminal에서 트랜젝션 종료 후 데이터 조회:
ROLLBACK;->SELECT * FROM auto;- 5번에서 추가된 데이터를 확인할 수 있다.
한 TRANSACTION 동안 조회되는 데이터가 정합성을 준수하는 걸 확인했다.
5.4 Serializable
위에 여러 read의 문제점을 해결하는 방법으로, 하나의 transaction에서 접근한 record에 lock을 걸어 다른 transaction이 동일한 데이터에 접근할 경우 이를 막아 transaction 간의 완전한 격리를 이루는 기능
문제점
- read도 lock을 획득해야만 가능하다.
- 이 전 isolation level에서는 read에 lock을 걸면 write만 할 수 없고, write에 lock을 걸면 read만 할 수 없었다.
- 하지만, read에 lock을 걸면 write나 update, delete 등을 실행할 수 없다.
- 그래서 시간이 많이 걸려 효율적이지 않아 사용하지 않는다.
해결책: default인 innodb 사용하기
InnoDB에서 repeatable read를 사용하면 serializable은 불필요하다.
6. 알아두면 좋은 명령어
SHOW CREATE TABLE {table name}
테이블이 어떻게 생성되었는지를 보여준다.
ORM으로 생성하면 실제 SQL에서 테이블을 어떻게 생성하는지 알기 어렵기 때문에 도움된다.
특히 회사에 갔을 때 기존에 생성된 테이블들이 어떤식으로 만들어졌는지 궁금하다면?!? 매우 유용하다.
ORM으로 테이블을 생성했을 때 본인의 의도와 다르다면 추가 학습이 필요하다.
charset
어떤 character(문자열)의 데이터를 저장할지
collate
저장된 데이터를 어떤식으로 비교, 정렬 할지
- 간단한 테이블에서는 문제가 되지 않는다